|
| csky_status | csky_mat_mult_f32 (const csky_matrix_instance_f32 *pSrcA, const csky_matrix_instance_f32 *pSrcB, csky_matrix_instance_f32 *pDst) |
| | 浮点矩阵乘法 更多...
|
| |
| csky_status | csky_mat_mult_fast_q15 (const csky_matrix_instance_q15 *pSrcA, const csky_matrix_instance_q15 *pSrcB, csky_matrix_instance_q15 *pDst, q15_t *pState) |
| | Q15 矩阵乘法 (快速版本) 更多...
|
| |
| csky_status | csky_mat_mult_fast_q31 (const csky_matrix_instance_q31 *pSrcA, const csky_matrix_instance_q31 *pSrcB, csky_matrix_instance_q31 *pDst) |
| | Q31 矩阵乘法 (快速版本) 更多...
|
| |
| csky_status | csky_mat_mult_q15 (const csky_matrix_instance_q15 *pSrcA, const csky_matrix_instance_q15 *pSrcB, csky_matrix_instance_q15 *pDst, q15_t *pState) |
| | Q15 矩阵乘法 更多...
|
| |
| csky_status | csky_mat_mult_q31 (const csky_matrix_instance_q31 *pSrcA, const csky_matrix_instance_q31 *pSrcB, csky_matrix_instance_q31 *pDst) |
| | Q31 矩阵乘法 更多...
|
| |
两个矩阵相乘
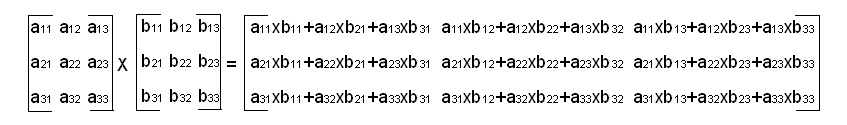
两个3 x 3矩阵相乘
只有第一个矩阵的列数和第二个矩阵的行数相等的时候,才可以做矩阵乘法 M x N 矩阵和 N x P 矩阵相乘的结果是一个 M x P矩阵. 当矩阵大小检查使能的时候,函数会检查: (1) pSrcA 和 pSrcB 的内部尺寸相等; (2) 输出矩阵的尺寸与 pSrcA 和 pSrcB 计算出来的尺寸相等.
- 参数
-
| [in] | *pSrcA | 指向第一个输入矩阵结构体 |
| [in] | *pSrcB | 指向第二个输入矩阵结构体 |
| [out] | *pDst | 指向输出矩阵结构体 |
| [in] | *pState | 指向保存中间结果的数组 |
- 返回
- 函数根据大小检查返回
CSKY_MATH_SIZE_MISMATCH 或者 CSKY_MATH_SUCCESS
缩放和溢出行为:
- 这个快速版本和函数 csky_mat_mult_q15() 的区别在于,快速版本使用了一个32位的累加器,而不是64位的累加器。 每个1.15和1.15相乘的结果截断为2.30的结果。 中间结果在2.30格式的32位寄存器累加。 最后累加器饱和转换为1.15格式的结果。
- 快速版本跟标准版本有相同的溢出行为,但是由于截断了每次相乘结果的低16位,所以提供的更低的精度。 为了防止溢出,必须缩小输入信号。 因为最多会有numColsA个加法进位,所以输入矩阵需要缩小 log2(numColsA) 个位,来防止溢出。
- 函数
csky_mat_mult_q15() 是这个函数的一个慢速版本,使用64位累加器提供更高的精度
- 参数
-
| [in] | *pSrcA | 指向第一个输入矩阵结构体 |
| [in] | *pSrcB | 指向第二个输入矩阵结构体 |
| [out] | *pDst | 指向输出矩阵结构体 |
- 返回
- 函数根据大小检查,返回
CSKY_MATH_SIZE_MISMATCH 或者 CSKY_MATH_SUCCESS
缩放和溢出行为:
- 这个快速版本和函数 csky_mat_mult_q31() 的区别在于,快速版本使用了一个32位的累加器,而不是64位的累加器。 每个1.31和1.31相乘的结果截断为2.30的结果。 中间结果在2.30格式的32位寄存器累加。 最后累加器饱和转换为1.31格式的结果。
- 快速版本跟标准版本有相同的溢出行为,但是由于截断了每次相乘结果的低32位,所以提供的更低的精度。 为了防止溢出,必须缩小输入信号。 因为最多会有numColsA个加法进位,所以输入矩阵需要缩小 log2(numColsA) 个位,来防止溢出。
- 函数
csky_mat_mult_q31() 是这个函数的一个慢速版本,使用64位累加器提供更高的精度。
- 参数
-
| [in] | *pSrcA | 指向第一个输入矩阵结构体 |
| [in] | *pSrcB | 指向第二个输入矩阵结构体 |
| [out] | *pDst | 指向输出矩阵结构体 |
| [in] | *pState | 指向保存中间结果的数组 (未使用) |
- 返回
- 函数根据大小检查返回
CSKY_MATH_SIZE_MISMATCH 或者 CSKY_MATH_SUCCESS
缩放和溢出行为:
- 函数实现使用了一个64位的内部累加器。输入都是1.15格式,相乘产生的结果是2.30格式。 2.30的中间结果在34.30格式的累加器累加。 因为提供了33个保护位,所有不会有溢出风险。 34.30的结果丢弃低15位,截断为34.15格式,然后饱和成1.15格式的最后结果
- 函数
csky_mat_mult_fast_q15() 是这个函数的一个快速版本,但是丢失了更多的精度
- 参数
-
| [in] | *pSrcA | 指向第一个输入矩阵结构体 |
| [in] | *pSrcB | 指向第二个输入矩阵结构体 |
| [out] | *pDst | 指向输出矩阵结构体 |
- 返回
- 函数根据大小检查返回
CSKY_MATH_SIZE_MISMATCH 或者 CSKY_MATH_SUCCESS
缩放和溢出行为:
- 函数实现使用了一个64位的内部累加器。 累加器使用2.62格式,维持了中间乘法结果的所有精度,但是只提供了1个保护位。 累加过程中没有饱和处理,累加器溢出会导致结果扭曲,因此必须缩小输入信号,防止溢出。 因为最多会有numColsA个加法进位,所以输入矩阵需要缩小 log2(numColsA) 个位,来防止溢出。 2.62格式的累加器右移31位,饱和生成1.31的最后结果。
- 函数
csky_mat_mult_fast_q31() 是这个函数的一个快速版本,但是丢失了更多的精度

