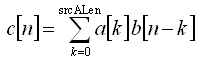|
| void | csky_conv_f32 (float32_t *pSrcA, uint32_t srcALen, float32_t *pSrcB, uint32_t srcBLen, float32_t *pDst) |
| | 浮点序列的卷积 更多...
|
| |
| void | csky_conv_fast_opt_q15 (q15_t *pSrcA, uint32_t srcALen, q15_t *pSrcB, uint32_t srcBLen, q15_t *pDst, q15_t *pScratch1, q15_t *pScratch2) |
| | Q15序列卷积 (快速版本) 更多...
|
| |
| void | csky_conv_fast_q15 (q15_t *pSrcA, uint32_t srcALen, q15_t *pSrcB, uint32_t srcBLen, q15_t *pDst) |
| | Q15序列的卷积 (快速版本) 更多...
|
| |
| void | csky_conv_fast_q31 (q31_t *pSrcA, uint32_t srcALen, q31_t *pSrcB, uint32_t srcBLen, q31_t *pDst) |
| |
| void | csky_conv_opt_q15 (q15_t *pSrcA, uint32_t srcALen, q15_t *pSrcB, uint32_t srcBLen, q15_t *pDst, q15_t *pScratch1, q15_t *pScratch2) |
| | Q15序列的卷积 更多...
|
| |
| void | csky_conv_opt_q7 (q7_t *pSrcA, uint32_t srcALen, q7_t *pSrcB, uint32_t srcBLen, q7_t *pDst, q15_t *pScratch1, q15_t *pScratch2) |
| | Q7序列的卷积 更多...
|
| |
| void | csky_conv_q15 (q15_t *pSrcA, uint32_t srcALen, q15_t *pSrcB, uint32_t srcBLen, q15_t *pDst) |
| | Q15序列的卷积 更多...
|
| |
| void | csky_conv_q31 (q31_t *pSrcA, uint32_t srcALen, q31_t *pSrcB, uint32_t srcBLen, q31_t *pDst) |
| | Q31序列的卷积 更多...
|
| |
| void | csky_conv_q7 (q7_t *pSrcA, uint32_t srcALen, q7_t *pSrcB, uint32_t srcBLen, q7_t *pDst) |
| | Q7序列的卷积 更多...
|
| |
卷积是一种控制两个有限向量生成一个有限向量的数学操作。 卷积类似于相关分析,经常用在过滤和数据分析。 CSI DSP库包括了Q7,Q15,Q31和浮点数据类型的卷积函数。
- 算法
- 令
a[n] 和 b[n] 分别是长度 srcALen 和 srcBLen 的样本序列. 则卷积是
c[n] = a[n] * b[n]
- 如下定义
- 注意:
c[n] 的长度是 srcALen + srcBLen - 1 ,并且在区间 n=0, 1, 2, ..., srcALen + srcBLen - 2 内. pSrcA 指向第一个输入长度向量 srcALen , pSrcB 指向第二个输入长度向量 srcBLen. 输出结果写入到 pDst ,调用函数必须为结果分配 srcALen+srcBLen-1 个字的空间。
- 概念上,当两个信号
a[n]和b[n]卷积时,信号b[n]在a[n]上滑动。 对于每个偏移 n ,a[n]和b[n]的重叠部分被相乘并相加在一起。
- 注意,卷积是可交换的操作:
a[n] * b[n] = b[n] * a[n].
- 这意味着交换A和B参数不会对卷积函数造成影响。
定点行为
- 卷积操作会产生大量的中间结果。 因此,Q7,Q15和Q31函数会有溢出和饱和的风险。 参考每个函数各自的文档说明,使用的算法的细节情况。
快速版本
- Q31和Q15支持快速版本。快速版本需要的周期数更少,但是需要缩放输入信号,确保不会引起中间值溢出
opt版本
- Q15和Q7有Opt版本. 设计使用内部buffer来达到更好的优化效果。 这些版本优化了速度,但是消耗更多的内存。
- 参数
-
| [in] | *pSrcA | 指向第一个输入序列 |
| [in] | srcALen | 第一个输入序列的长度 |
| [in] | *pSrcB | 指向第二个输入序列 |
| [in] | srcBLen | 第二个输入序列的长度 |
| [out] | *pDst | 指向输出结果的地址,长度是 srcALen+srcBLen-1. |
- 返回
- none.
| void csky_conv_fast_opt_q15 |
( |
q15_t * |
pSrcA, |
|
|
uint32_t |
srcALen, |
|
|
q15_t * |
pSrcB, |
|
|
uint32_t |
srcBLen, |
|
|
q15_t * |
pDst, |
|
|
q15_t * |
pScratch1, |
|
|
q15_t * |
pScratch2 |
|
) |
| |
- 参数
-
| [in] | *pSrcA | 指向第一个输入序列 |
| [in] | srcALen | 第一个输入序列的长度 |
| [in] | *pSrcB | 指向第二个输入序列 |
| [in] | srcBLen | 第二个输入序列的长度 |
| [out] | *pDst | 指向输出结果的地址,长度是 srcALen+srcBLen-1. |
| [in] | *pScratch1 | 指向临时buffer,大小是 max(srcALen, srcBLen) + 2*min(srcALen, srcBLen) - 2. |
| [in] | *pScratch2 | 指向临时buffer,大小是 min(srcALen, srcBLen). |
- 返回
- none.
- 限制
- 如果芯片不支持分对齐访问,则定义宏 UNALIGNED_SUPPORT_DISABLE。 同时,输入,输出,临时buffer,都应该是32位对齐。
缩放和溢出行为:
- 这个快速版本使用一个格式为2.30的32位累加器。 累加器维持了中间相乘结果的所有精度,但是只有一个保护位。 因为中间加法没有饱和操作,所以,累加器如果溢出的话,会往符号位溢出,扭曲结果。
输入信号需要缩放到防止中间结果溢出。 因为,最多可能有 min(srcALen, srcBLen) 个内部加法进位,所以输入需要缩放 log2(min(srcALen, srcBLen)) (log2 是2为底的对数) 倍。 2.30格式的累加器右移15位,并且饱和到1.15格式生成最后的结果。
- 见
csky_conv_q15() ,这个函数是一个慢速实现,使用了64位累加器,来防止精度丢失。
| void csky_conv_fast_q15 |
( |
q15_t * |
pSrcA, |
|
|
uint32_t |
srcALen, |
|
|
q15_t * |
pSrcB, |
|
|
uint32_t |
srcBLen, |
|
|
q15_t * |
pDst |
|
) |
| |
- 参数
-
| [in] | *pSrcA | 指向第一个输入序列 |
| [in] | srcALen | 第一个输入序列的长度 |
| [in] | *pSrcB | 指向第二个输入序列 |
| [in] | srcBLen | 第二个输入序列的长度 |
| [out] | *pDst | 指向输出结果的地址,长度是 srcALen+srcBLen-1. |
- 返回
- none.
缩放和溢出行为:
- 这个快速版本使用一个格式为2.30的32位累加器。 累加器维持了中间相乘结果的所有精度,但是只有一个保护位。 因为中间加法没有饱和操作,所以,累加器如果溢出的话,会往符号位溢出,扭曲结果。
输入信号需要缩放到防止中间结果溢出。 因为,最多可能有 min(srcALen, srcBLen) 个内部加法进位,所以输入需要缩放 log2(min(srcALen, srcBLen)) (log2 是2为底的对数) 倍。 2.30格式的累加器右移15位,并且饱和到1.15格式生成最后的结果。
- 见
csky_conv_q15() ,这个函数是一个慢速实现,使用了64位累加器,来防止精度丢失。
| void csky_conv_fast_q31 |
( |
q31_t * |
pSrcA, |
|
|
uint32_t |
srcALen, |
|
|
q31_t * |
pSrcB, |
|
|
uint32_t |
srcBLen, |
|
|
q31_t * |
pDst |
|
) |
| |
- 参数
-
| [in] | *pSrcA | 指向第一个输入序列 |
| [in] | srcALen | 第一个输入序列的长度 |
| [in] | *pSrcB | 指向第二个输入序列 |
| [in] | srcBLen | 第二个输入序列的长度 |
| [out] | *pDst | 指向输出结果的地址,长度是 srcALen+srcBLen-1. |
- 返回
- none.
缩放和溢出行为:
- 该函数针对速度进行了优化,牺牲了定点精度和溢出保护. 每个 1.31 和 1.31 相乘的结果截断为 2.30 格式. 这些中间结果以2.30格式在一个32位寄存器中累加. 最后,累加器饱和转换为 1.31 结果.
- 快速版本具有与标准版本相同的溢出行为,但提供较小的精度,因为它丢弃每个乘法结果的低32位 为了避免溢出,输入信号必须缩放。 因为,最多可能有 min(srcALen, srcBLen) 个内部加法进位,所以输入需要缩放 log2(min(srcALen, srcBLen)) (log2 是2为底的对数) 倍。
- 见
csky_conv_q31() ,这个函数是一个慢速实现,使用了64位累加器,来防止精度丢失。
| void csky_conv_opt_q15 |
( |
q15_t * |
pSrcA, |
|
|
uint32_t |
srcALen, |
|
|
q15_t * |
pSrcB, |
|
|
uint32_t |
srcBLen, |
|
|
q15_t * |
pDst, |
|
|
q15_t * |
pScratch1, |
|
|
q15_t * |
pScratch2 |
|
) |
| |
- 参数
-
| [in] | *pSrcA | 指向第一个输入序列 |
| [in] | srcALen | 第一个输入序列的长度 |
| [in] | *pSrcB | 指向第二个输入序列 |
| [in] | srcBLen | 第二个输入序列的长度 |
| [out] | *pDst | 指向输出结果的地址,长度是 srcALen+srcBLen-1. |
| [in] | *pScratch1 | 指向临时buffer,大小是 max(srcALen, srcBLen) + 2*min(srcALen, srcBLen) - 2. |
| [in] | *pScratch2 | 指向临时buffer,大小是 min(srcALen, srcBLen). |
- 返回
- none.
- 限制
- 如果芯片不支持分对齐访问,则定义宏 UNALIGNED_SUPPORT_DISABLE 同时,输入,输出,临时buffer,都应该是32位对齐。
缩放和溢出行为:
- 函数实现使用了一个内部64位内部累加器。 输入都是1.15格式,相乘结果是2.30格式。 2.30的中间结果在64位累加器中以34.30格式保存。 这种方法提供了33个保护位,因此没有溢出的风险。 最后,34.30格式的结果丢弃低15位截断为34.15格式,然后饱和成1.15格式的结果。
- 参考
csky_conv_fast_q15() ,是一个快速,但是降低了精度的实现版本。
| void csky_conv_opt_q7 |
( |
q7_t * |
pSrcA, |
|
|
uint32_t |
srcALen, |
|
|
q7_t * |
pSrcB, |
|
|
uint32_t |
srcBLen, |
|
|
q7_t * |
pDst, |
|
|
q15_t * |
pScratch1, |
|
|
q15_t * |
pScratch2 |
|
) |
| |
- 参数
-
| [in] | *pSrcA | 指向第一个输入序列 |
| [in] | srcALen | 第一个输入序列的长度 |
| [in] | *pSrcB | 指向第二个输入序列 |
| [in] | srcBLen | 第二个输入序列的长度 |
| [out] | *pDst | 指向输出结果的地址,长度是 srcALen+srcBLen-1. |
| [in] | *pScratch1 | 指向临时buffer,大小是 max(srcALen, srcBLen) + 2*min(srcALen, srcBLen) - 2. |
| [in] | *pScratch2 | 指向临时buffer,大小是 min(srcALen, srcBLen). |
- 返回
- none.
- 限制
- 如果芯片不支持分对齐访问,则定义宏 UNALIGNED_SUPPORT_DISABLE 同时,输入,输出,临时buffer,都应该是32位对齐。
缩放和溢出行为:
- 函数实现使用了一个内部32位累加器。 输入都表示为1.7格式,相乘的结果是2.14格式。 2.14的中间结果在18.14格式的32位累加器中累加。 由于有17个守护位,除非
max(srcALen, srcBLen)大于131072,否则不会溢出。 18.14格式的结果丢弃低7位,截断为18.7格式,然后再饱和成1.7格式。
| void csky_conv_q15 |
( |
q15_t * |
pSrcA, |
|
|
uint32_t |
srcALen, |
|
|
q15_t * |
pSrcB, |
|
|
uint32_t |
srcBLen, |
|
|
q15_t * |
pDst |
|
) |
| |
- 参数
-
| [in] | *pSrcA | 指向第一个输入序列 |
| [in] | srcALen | 第一个输入序列的长度 |
| [in] | *pSrcB | 指向第二个输入序列 |
| [in] | srcBLen | 第二个输入序列的长度 |
| [out] | *pDst | 指向输出结果的地址,长度是 srcALen+srcBLen-1. |
- 返回
- none.
缩放和溢出行为:
- 函数实现使用了一个内部64位累加器。 输入都表示为1.15格式,相乘的结果是2.30格式。 2.30的中间结果在34.30格式的64位累加器中累加。 由于有33个守护位,所以应该不会有溢出 34.30格式的结果丢弃低15位,截断为34.15格式,然后再饱和为1.15格式。
- 函数
csky_conv_fast_q15() 是一个快速版本,但是丢失了更多的精度。
- 函数
csky_conv_opt_q15() 是一个快速版本,使用了额外的临时缓存空间。
| void csky_conv_q31 |
( |
q31_t * |
pSrcA, |
|
|
uint32_t |
srcALen, |
|
|
q31_t * |
pSrcB, |
|
|
uint32_t |
srcBLen, |
|
|
q31_t * |
pDst |
|
) |
| |
- 参数
-
| [in] | *pSrcA | 指向第一个输入序列 |
| [in] | srcALen | 第一个输入序列的长度 |
| [in] | *pSrcB | 指向第二个输入序列 |
| [in] | srcBLen | 第二个输入序列的长度 |
| [out] | *pDst | 指向输出结果的地址,长度是 srcALen+srcBLen-1. |
- 返回
- none.
缩放和溢出行为:
- 函数实现使用了一个内部64位累加器。 累加器使用2.62格式维持所有的中间乘法结果的精度,但是只有一个保护位 累加过程中没有饱和操作。 如果累加器溢出,会往符号位溢出,扭曲结果。 因此,输入信号需要缩小来防止溢出。 因为加法过程中最多会有min(srcALen, srcBLen)次进位,所以,输入需要缩小 log2(min(srcALen, srcBLen)) (log2是2为底的对数) 倍来防止溢出。 2.62格式的累加器,右移31位,再饱和生成1.31格式的最后结果。
csky_conv_fast_q31() 是一个快速版本,但是丢失了更多精度。
| void csky_conv_q7 |
( |
q7_t * |
pSrcA, |
|
|
uint32_t |
srcALen, |
|
|
q7_t * |
pSrcB, |
|
|
uint32_t |
srcBLen, |
|
|
q7_t * |
pDst |
|
) |
| |
- 参数
-
| [in] | *pSrcA | 指向第一个输入序列 |
| [in] | srcALen | 第一个输入序列的长度 |
| [in] | *pSrcB | 指向第二个输入序列 |
| [in] | srcBLen | 第二个输入序列的长度 |
| [out] | *pDst | 指向输出结果的地址,长度是 srcALen+srcBLen-1. |
- 返回
- none.
缩放和溢出行为:
- 函数使用了一个内部32位累加器。 输入都用1.7格式表示,相乘的结果是2.14格式。 2.14的中间结果在18.14格式的32位累加器中累加。 由于有17个守护位,除非
max(srcALen, srcBLen)大于131072,否则不会溢出。 18.14格式的结果丢弃低7位,截断为18.7格式,然后再饱和成1.7格式
- 函数
csky_conv_opt_q7() 是这个函数的一个快速版本。